
我们提供安全,免费的手游软件下载!
最近在搞分布式训练大模型,踩了两个晚上的坑今天终于爬出来了。我们使用2台8*H100,遇到了以下三个错误。
错误1
10.255.19.85: ncclSystemError: System call (e.g. socket, malloc) or external library call failed or device error.
10.255.19.85: Last error:
10.255.19.85: socketStartConnect: Connect to 127.0.0.1<34273> failed : Software caused connection abort
错误2
10.255.19.82: torch.distributed.DistBackendError: [7] is setting up NCCL communicator and retrieving ncclUniqueId from [0] via c10d key-value store by key '0', but store->get('0') got error: Connection reset by
错误3
10.255.19.85: ncclInternalError: Internal check failed.
10.255.19.85: Last error:
10.255.19.85: Bootstrap : no socket interface found
其实这三个错误都是一个问题导致的,就是网卡配置的问题。
这是之前的配置
hostfile
fine-tune.sh
修改后之后的配置
问题主要出现在 NCCL_SOCKET_IFNAME 这个环境变量,这个环境变量会被携带到其他机器上,但是网卡的名称是不一样的,尤其我的两台机器包含很多的网卡,因此,我们配置的时候需要把那些没用的虚拟网卡屏蔽掉,只留下需要的。
解决方法,这个要根据实际情况来改,英伟达官方写法如下,屏蔽显卡用^开头

我的网卡太多了,之前一直以为环境变量在 /etc/profile 下配置各自的就行,然后再source /etc/profile,结果发现不对,从机也都指向了主机的网卡,没办法建立socket。

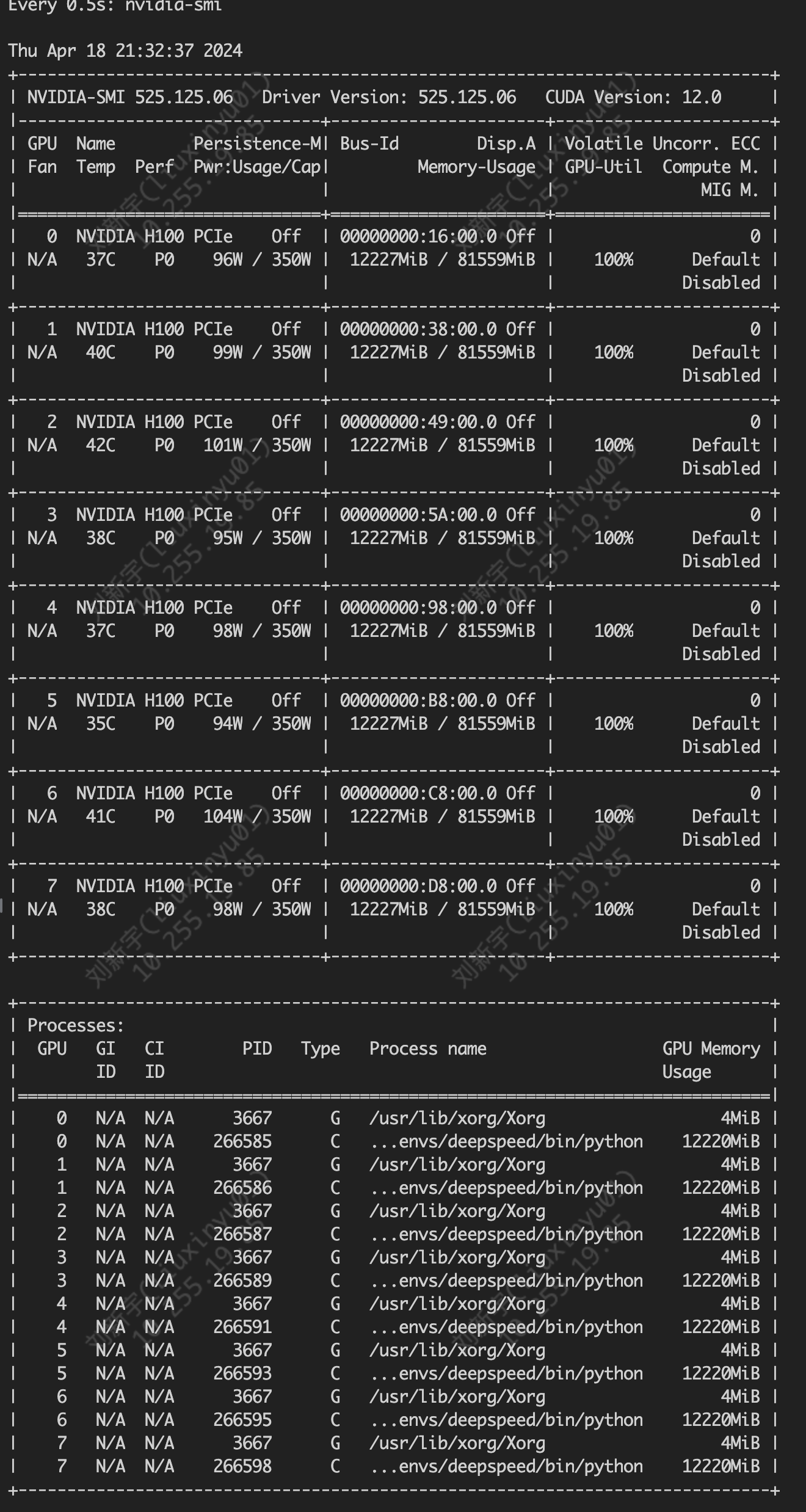
修改后成功跑起16*H100,爽歪歪。

热门资讯

















