
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 GitHub官方地址: GLM-4
在网络上已经有很多关于微调的文章,介绍了各种使用方式,但很少有文章涉及微调时的loss计算逻辑。本文将深入探讨微调过程中的loss计算逻辑,以及相关源码分析。
如果想了解其他loss计算的文章,可以参考以下链接:
再聊多轮对话微调训练格式与长序列训练
聊聊ChatGLM2与ChatGLM3微调多轮对话的设计逻辑及源码分析
聊聊大模型多轮对话的训练及优化
微调源码地址: finetune.py
微调的格式如下:
[
{
"messages": [
{
"role": "system",
"content": "",
"tools": [
{
"name": "",
"args": {
"": ""
}
}
]
},
...
]
}
]
Loss计算代码:
def process_batch(
batch: Mapping[str, Sequence],
tokenizer: PreTrainedTokenizer,
max_input_length: int,
max_output_length: int,
) -> dict[str, list]:
# 代码逻辑...
process_batch方法用于将输入转换为ids,并计算mask(用于Loss计算)。该方法在数据集的遍历处理中被调用。
Loss计算如下图所示:
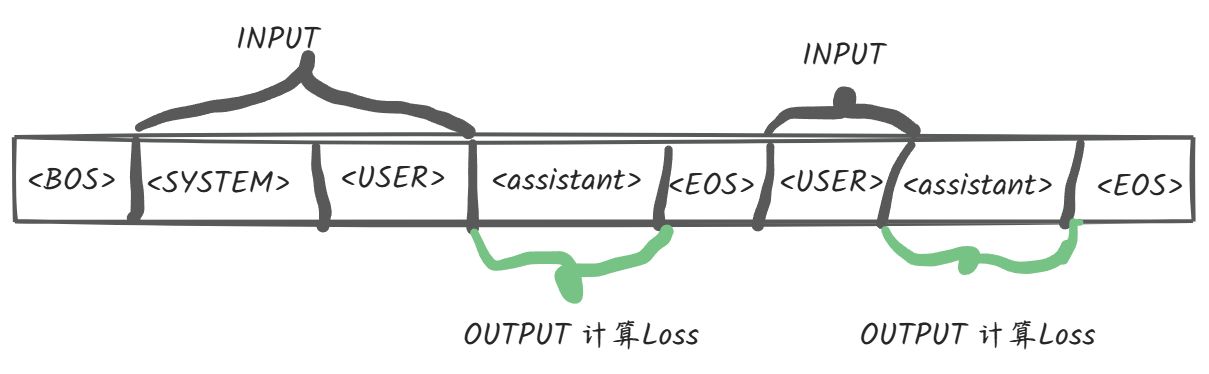
相比之前的ChatGLM版本,GLM4开源版本的多轮对话loss计算更恰当且效率更高。在其他的开源模型/微调框架中早已支持该种loss计算,如InternLM、XTuner、Firefly等。对于loss格式的类别,可参考XTuner的官方文档说明: dataset_format.md 。
原文链接: https://mp.weixin.qq.com/s/0mLCQfpaZr7eEonG4a4Etg
更多大模型相关的文章,请上个人公众号查阅:

热门资讯







