
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 本文分享自华为云社区《【华为云MySQL技术专栏】MySQL中为什么要使用索引合并(Index Merge)?》,作者:GaussDB 数据库。
在生产环境中,MySQL语句的where查询通常会包含多个条件判断,以AND或OR操作进行连接。然而,对一个表进行查询最多只能利用该表上的一个索引,其他条件需要在回表查询时进行判断(不考虑覆盖索引的情况)。当回表的记录数很多时,需要进行大量的随机IO,这可能导致查询性能下降。因此,MySQL 5.x 版本推出索引合并(Index Merge)来解决该问题。
本文将基于MySQL 8.0.22版本对MySQL的索引合并功能、实现原理及场景约束进行详细介绍,同时也会结合原理对其优缺点进行浅析,并通过例子进行验证。
索引合并是通过对一个表同时使用多个索引进行条件扫描,并将满足条件的多个主键集合取交集或并集后再进行回表,可以提升查询效率。
索引合并主要包含交集(intersection),并集(union)和排序并集(sort-union)三种类型:
MySQL中有四个开关(index_merge、index_merge_intersection、index_merge_union以及index_merge_sort_union)对上述三种索引合并类型提供支持,可以通过修改optimizer_switch系统参数中的四个开关标识来控制索引合并特性的使用。
假设创建表T,并插入如下数据:
默认情况下,四个开关均为开启状态。如果需要单独使用某个合并类型,需设置index_merge=off,并将相应待启用的合并类型标识(例如,index_merge_sort_union)设置为on。
开关开启后,可通过EXPLAIN执行计划查看当前查询语句是否使用了索引合并。
上面代码显示type类型为index_merge,表示使用了索引合并。key列显示使用到的所有索引名称,该语句中同时使用了idx_a和idx_b两个索引完成查询。Extra列显示具体使用了哪种类型的索引合并,该语句显示Using union(...),表示索引合并类型为union。
此外,可以使用index_merge/no_index_merge给查询语句添加hint,强制SQL语句使用/不使用索引合并。
• 如果查询默认未使用索引合并,可以通过添加index_merge强制指定:
• 使用no_index_merge给查询语句添加hint,可以忽略索引合并优化:
Index Merge Intersection会在使用到的多个索引上同时进行扫描,并取这些扫描结果的交集作为最终结果集。
以“SELECT * FROM T WHERE a=1 AND b='C'; ”语句为例:
• 未使用索引合并时,MySQL利用索引idx_a获取到满足条件a=1的所有主键id,根据主键id进行回表查询到相关记录,随后再使用条件b='C'对这些记录进行判断,获取最终查询结果。
• 使用索引合并时,MySQL分别利用索引idx_a和idx_b获取满足条件a=1和b='C'的主键id集合setA和setB。随后取setA和setB中主键id的交集setC,并使用setC中主键id进行回表,获取最终查询结果。
执行流程如下:
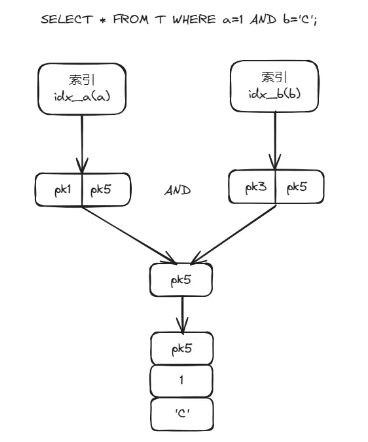
图1 SELECT * FROM T WHERE a=1 AND b='C';执行流程
Index Merge Union会在使用到的多个索引上同时进行扫描,并取这些扫描结果的并集作为最终结果集。
以“SELECT * FROM T WHERE a=1 OR b='B'; ”语句为例:
• 未使用索引合并时,MySQL通过全表扫描获取所有记录信息,随后再使用条件a=1和b='B'对这些记录进行判断,获取最终查询结果。
• 使用索引合并算法时,MySQL分别利用索引idx_a和idx_b获取满足条件a=1和b='B'的主键id集合setA和setB。随后,取setA和setB中主键id的并集setC,并使用setC中主键id进行回表,获取最终查询结果。
执行流程如下:
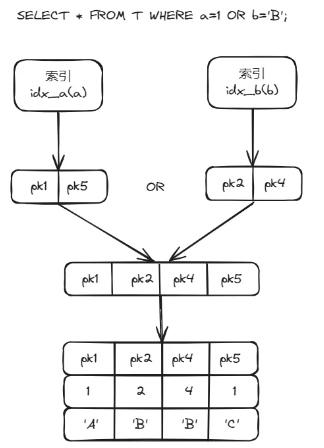
图2 SELECT * FROM T WHERE a=1 OR b='B';执行流程
Sort-Union索引合并与Union索引合并原理相似,只是比单纯的Union索引合并多了一步对二级索引记录的主键id排序的过程。由OR连接的多个范围查询条件组成的WHERE子句不满足Union算法时,优化器会考虑使用Sort-Union算法。例如:
以上约束适用于Intersection,Union和Sort-Union三种合并类型。此外,Intersection和Union存在特殊的场景约束。
使用Intersection要求AND连接的每个条件必须是如下形式之一:
(1) 当索引包含多个列时,每个列都必须被如下等值条件覆盖,不允许出现范围查询。若使用索引为联合索引时,每个列都必须等值匹配,不能出现只匹配部分列的情况。
(2) 若过滤条件中存在主键列,主键列可以进行范围匹配。
上述的要求,本质上是为了确保索引取出的记录是按照主键id有序排列的,因为Index Merge Intersection对两个有序集合取交集更简单。同时,主键有序的情况下,回表将不再是单纯的随机IO,回表的效率也会更高。
使用Union要求OR连接的每个条件,必须是如下形式之一:
(1) 当索引包含多个列时,则每个列都必须被如下等值条件覆盖,不允许出现范围查询。若使用索引为联合索引时,在联合索引中的每个列都必须等值匹配,不能出现只匹配部分列的情况。
(2) 若过滤条件中存在主键列,主键列可以进行范围匹配。
• Index Merge Intersection在使用到的多个索引上同时进行扫描,并取这些扫描结果的并集作为最终结果集。
当优化器根据搜索条件从某个索引中获取的记录数极多时,适合使用Intersection对取交集后的主键id以顺序I/O进行回表,其开销远小于使用随机IO进行回表。反之,当根据搜索条件扫描出的记录极少时,因为需要多一步合并操作,Intersection反而不占优势。在8.0.22版本,对于AND连接的点查场景,通过建立联合索引可以更好的减少回表。
• Index Merge Union在使用到的多个索引上同时进行扫描,并取这些扫描结果的并集作为最终结果集。
当优化器根据搜索条件从某个索引中获取的记录数比较少,通过Union索引合并后进行访问的代价比全表扫描更小时,使用Union的效果才会更优。
• Index Merge Sort-Union比单纯的Union索引合并多了一步对索引记录的主键id排序的过程。
当优化器根据搜索条件从某个索引中获取的记录数比较少的时,对这些索引记录的主键id进行排序的成本不高,此时可以加速查询。反之,当需要排序的记录过多时,该算法的查询效率不一定更优。
我们以Index Merge Union为例,对上述分析进行验证。
每条语句查询5次,去掉最大值和最小值,取剩余三次结果平均值。4条语句查询结果如下:
|
测试语句 |
第一次查询/ms |
第二次查询/ms |
第三次查询/ms |
第四次查询/ms |
第五次查询/ms |
平均值/ms |
|---|---|---|---|---|---|---|
|
SQL1 |
5.481 |
5.422 |
5.117 |
4.892 |
5.426 |
5.322 |
|
SQL2 |
31.129 |
32.645 |
30.943 |
31.142 |
32.625 |
31.632 |
|
SQL3 |
7.872 |
7.200 |
7.824 |
7.955 |
7.949 |
7.882 |
|
SQL4 |
31.139 |
33.318 |
31.476 |
31.645 |
31.27 |
31.464 |
对比使用索引合并的SQL1和未使用索引合并的SQL2的查询结果可知,使用索引合并的SQL1具有更高的查询效率,这点从语句的explain analyze分析中也可以看出:
使用索引合并的SQL1代码示例:
未使用索引合并的SQL2代码示例:
未使用索引合并时,SQL2语句需要花费约23ms来扫描全表100001行数据,随后再进行条件判断。而使用索引合并时,通过合并两个索引筛选出的主键id集合,筛选出2056个符合条件的主键id, 随后回表获取最终的数据。这个环节中,索引合并大大减少了需要访问的记录数量。
此外,从SQL1和SQL3的查询结果也可以看出,数据分布也会影响索引合并的效果。相同的SQL模板类型,根据匹配数值的不同,查询时间存在差异。如需要合并的主键id集合越小,需要回表的主键id越少,查询时间越短。
本文介绍了索引合并(Index Merge)包含的三种类型,即交集(intersection)、并集(union)和排序并集(sort-union),以及索引合并的实现原理、场景约束与通过案例验证的优缺点。在实际使用中,当查询条件列较多且无法使用联合索引时,就可以考虑使用索引合并,利用多个索引加速查询。但要注意,索引合并并非在任何场景下均具有较好的效果,需要结合具体的数据分布进行算法的选择。
点击关注,第一时间了解华为云新鲜技术~
热门资讯







