
我们提供安全,免费的手游软件下载!
 米仓漫画 免费版
米仓漫画 免费版  枫牙漫画
枫牙漫画  漫天玉漫画 官网版下载正版
漫天玉漫画 官网版下载正版  漫天玉漫画 app2025官方版
漫天玉漫画 app2025官方版  特盐阅读 免费阅读
特盐阅读 免费阅读  游咔 app官方版下载
游咔 app官方版下载  亿雪影院 新版
亿雪影院 新版  SlookTV 官网版
SlookTV 官网版  clicli动漫 正版无广告
clicli动漫 正版无广告  飞沙电视 tv版安装
飞沙电视 tv版安装 现在商用优化器大多都是基于统计信息进行查询代价评估。因此,统计信息的实时性和准确性对查询影响很大,特别是在分布式数据库场景下。本文详细介绍了GaussDB(DWS)如何实现了一种轻量、实时、准确的统计信息自动收集方案。
本文分享自华为云社区《【最佳实践】GaussDB(DWS) 统计信息自动收集方案》,作者:leapdb。
何时做analyze,多做空耗系统资源,少做统计信息不及时。
多个数据源并发加工一张表,手动analyze不能并发。
数据修改后立即查询,统计信息实时性要求高。
需要关心每张表的数据变化和治理,消耗大量人力。
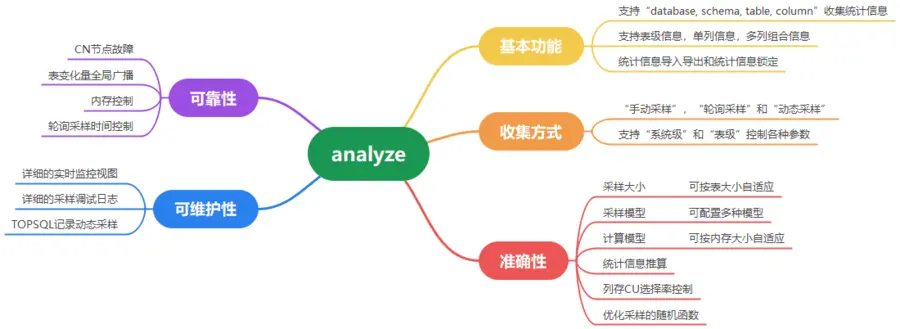
GaussDB(DWS) 支持统计信息自动收集功能,主要解决统计信息收集不及时和不准确的问题。
手动采样:用户在作业中,手动发起的显示analyze。
轮询采样:autovacuum后台线程,轮询发起的analyze。
动态采样:查询时,优化器触发的runtime analyze。
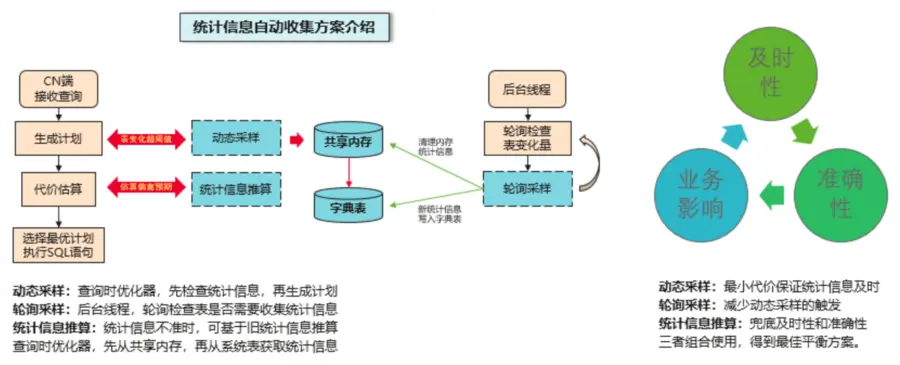
前台动态采样:负责统计信息实时准确,信息放内存(有淘汰机制),一级锁(像查询一样轻量)。
后台轮询采样:负责统计信息的持久化,写系统表(四级锁),不要求特别及时。
二者都需要开启。
统计信息基于收集时表数据生成,数据变化较多后可能失效。自动触发也是基于阈值(50+表大小*10%)。
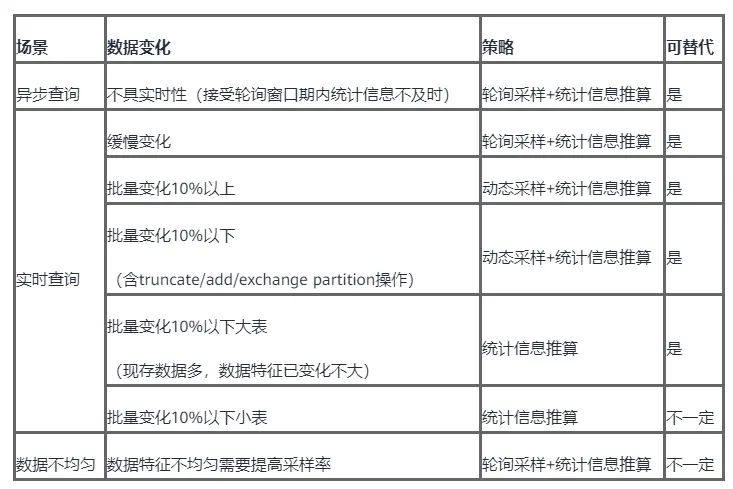
总结:
【触发条件】“无统计信息” or “表的修改量超过一定阈值(默认“50 + 表大小 * 10%”)”
【触发场景】含stream计划的SQL都可触发动态采样,包括select和带条件的delete, update。
【修改计数】
DML: Insert, Update, Delete, Copy, Merge,会累加修改计数。
DDL: truncate table,truncate/exchange/drop partition, alter column type, alter distribute,由于CN无法获取DN修改计数,所以直接记录一个超大修改计数。
异步广播:autovacuum后台线程轮询检查时,向所有CN广播全局修改计数。修改计数达2/3时广播一次,此后每增10%再广播一次。
实时广播:单SQL修改超过tuple_change_sync_threshold(默认1W)条时,直接实时广播修改计数到其它CN。
总结:“修改计数记录”和“修改计数广播”,覆盖都比较全面,能够保证查询及时触发动态采样。
GaussDB(DWS) analyze使用指南8.1.3及以下版本
GaussDB(DWS) analyze使用指南8.2.0及以上版本
【业务场景】

【问题根因】
a. 某数据湖用户,多个数据源按照不同的分区进行数据导入加工。
b. 事务块中有手动analyze,且事务块中后面的查询长时间执行不完。
c. 因analyze对表加四级锁长时间不能释放,导致其它相关表上的业务等锁超时报错。
【解决方案】开启light动态采样,去掉事务块中的手动analyze。
【业务场景】
为了保证用户查询表总有数据,需要把加工过程放到一个事务里面。堵塞其它人的动态采样。
【问题根因】alter table truncate parition对分区加8级锁,事务过程中长时间持锁。
【解决方案】使用exchange partition
【业务场景】
a. 某银行客户,多个表进行批处理数据加工,开启了normal类型动态采样。
b. 查询A先对t1表触发动态采样,再对t2表触发动态采样。
c. 查询B先对t2表触发动态采样,再对t1表触发动态采样。
d. 触发动态采样的顺序不一致,互相申请四级锁导致申锁超时,统计信息未收集。
【问题根因】多人同时按不同顺序analyze多表导致死锁。
【解决方案】开启light动态采样,仅加一级锁不再有四级锁冲突。
【业务场景】
a. 某财经用户,按照月度视为会计期,月初时导入少量数据,然后马上查询。
b. 触发了动态采样,但采集不到最新会计期的少量数据。
【问题根因】新插入数据占比小,及时触发了动态采样但采集不到,导致估算偏差大。
【解决方案】
a. 开启统计信息推算enable_extrapolation_stats功能,根据上一个会计期的统计信息推算当前会计期数据特征。
b. 不提高采样大小,利用历史信息增强统计信息准确性。
【业务场景】
a. 某银行客户,按月度条件进行关联查询
b. 多次analyze,最多数据月份在MCV中占比从13%~30%大幅波动
c. 详细输出样本点位置和采样随机数发现,随机数(小数点后6位)生成重复度高导致采样扎堆儿严重。
【问题根因】采样随机数不够随机,样本采集不均匀导致MCV数据特征统计偏差。
【解决方案】
a. 每次传入随机种子再生成随机数,提高随机性和并发能力。控制参数random_function_version。
b. 不提高采样大小,提升随机数质量增强统计信息准确性。
【业务场景】
a. tpc-h的lineitem表l_orderkey列,数据每4~8条批量重复。即同一个订单购买多个商品。
b. 传统采样算法由于采样不均匀,采集到的重复数据稍多,导致采集的distinct值偏低。
【问题根因】数据特征分布不均匀,采样无法抓准数据特征,distinct值高的场景统计出的distinct值偏低。
【解决方案】
a. 使用自研的优化蓄水池采样算法,控制参数analyze_sample_mode=2,让采样更加均匀,以提升统计信息准确性。
b. 如果上述方法没有达到预期效果,可以手动修改distinct值。
点击关注,第一时间了解华为云新鲜技术~
相关资讯
热门资讯







