
我们提供安全,免费的手游软件下载!
 米仓漫画 免费版
米仓漫画 免费版  枫牙漫画
枫牙漫画  漫天玉漫画 官网版下载正版
漫天玉漫画 官网版下载正版  漫天玉漫画 app2025官方版
漫天玉漫画 app2025官方版  特盐阅读 免费阅读
特盐阅读 免费阅读  游咔 app官方版下载
游咔 app官方版下载  亿雪影院 新版
亿雪影院 新版  SlookTV 官网版
SlookTV 官网版  clicli动漫 正版无广告
clicli动漫 正版无广告  飞沙电视 tv版安装
飞沙电视 tv版安装 关于REACT范式的一些思考
REACT范式经过近一年的探索,让我们在很多领域有了非常广泛的应用,它确实提升了很多之前无法解决的问题,比如大模型虽然在语言理解和交互式决策方面在任务中表现出令人印象深刻的表现,但是如何让模型基于解释来使用 LLMs 以交错方式生成推理跟踪和特定于任务的操作 一直是一个问题,REACT范式提出了一种,模仿人类在“行动”和“推理”之间的这种紧密协同作用,并且模仿人类快速学习新任务并执行稳健的决策或推理,即使在以前看不见的情况下或面临信息不确定性。
说明了经过上一小结的实验,REACT表现由于ACT,表 1 显示了使用 PaLM540B 作为基础模型和不同提示方法的 HotpotQA 和 Fever 结果。我们注意到,在这两项任务上,REACT 都优于 Act,这证明了推理在指导行动方面的价值,尤其是在综合最终答案方面,如图 1 (1c-d) 所示。微调结果 3 也证实了推理跟踪的好处,可以做出更明智的行为。

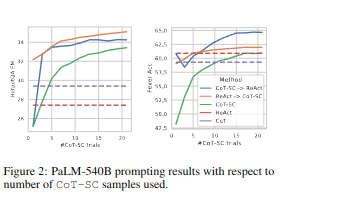
在REACT 和 CoT 在 HotpotQA 上的行为差异,作者设计了一种ROC测量评判分类、检测结果的好坏,实验步骤如下
分别从 REACT 和 CoT 中随机抽取了 50 个正确和错误答案(由 EM 判断)的轨迹(总共 200 个示例),并在表 2 中手动标记了它们的成功和失败模式。
B) 说明了 一些问题,包括接地性(grounded-ness)和可信度(trustworthiness),虽然相比CoT,REACT的推理、动作和观察步骤交错提高了,但这种结构约束也降低了REACT制定推理步骤的灵活性,导致推理错误率高于CoT。
REACT经常会出现一个错误模式,即模型重复生成之前的想法和行动,我们将其归类为“推理错误”的一部分,因为模型无法推理出下一步应该采取什么正确的行动并跳出循环。(这里也许可以通过工程上下文问题尝试解决,不过会进一步增加推理成本,law法律比赛中尝试了使用这种方式)
C)这里作者并没有解决 检索信息性知识准确性 ,在原实验中无信息性搜索占错误案例的 23%,它破坏了模型推理,并使其难以恢复和重新表述思想。
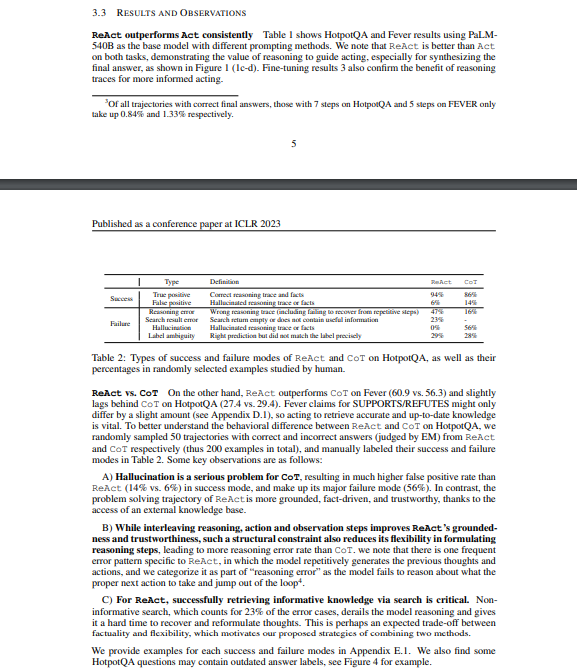
论文最终给了一个结果,在它所实验的样本中,REACT + CoT-SC 的提示LLMs效果最好,仅使用 3-5 个样本即可达到 21 个样本的 CoT-SC 性能。这些结果表明,正确结合模型内部知识和外部知识对于推理任务具有价值。
论文总体的思想提到的一个范式如下
Question
Thought
Action [Finish]
Observation
在3.3 RESULTS AND OBSERVATIONS中,讨论的诸多问题,看起来都归结到了模型幻觉上,观察下来,从解释行动的语言学角度来看,模型在对问题做出解释(Thought)在做出下一步行动,这一个过程中是什么驱使行动的发生呢,显然这里并没有讨论,出现问题的地方也许是模型幻觉,也许是更深度的问题
这里我们不做探讨,我们从行动发生的成功率来讨论,显然我们需要找到一种高效的评估方法,我们可以继续采用ROC这个方法来评估,列出真、幻觉、假等指标的混淆矩阵,让模型尝试学习来提升这一步的效果,
上面这步也许能有些作用,但实际上,前面提到的诸多问题,真的只是这个么,我们观察下 “chain-of-thought” 中断的条件是reasoning,前面提到REACT + CoT-SC 实际是
这又是一个复杂的问题,我们应该如何解决呢,emmm我也不知道,先说无法解决这个问题不是因为解决不了,而是这个问题非常复杂,
当模型触发动作去查询到了一个信息,这个过程,实际上是脱离了上面的范式覆盖的过程,动作被触发后,也许是一个数据查询,也许是一个按钮操作,这些脱离之后的行为,最终会到Observation,又进一步的进行使用模型能力判断,是否真的Action [Finish],如此往复下来,模型的上下文会非常大,可能是无用的信息,最终Observation之后的COT,也许因为上下文的庞大无法处理,也许我们不关注上下文长度能解决呢?事实真的是这样吗
那请你思考这个问题“从前有做山,山上有做庙。庙里有个老和尚在跟小和尚讲故事,讲的是。。。”
我们看到了一个循环,这里是一个我目前无法言说的内容,也许我需要提升下,下面是GPT的解释,也许你能理解我说的是什么
#### 循环的本质
那请你思考这个问题“从前有做山,山上有做庙。庙里有个老和尚在跟小和尚讲故事,讲的是……”
我们看到了一个循环。
这个循环并不仅仅是一个逻辑上的陷阱,它也可能是理解推理过程的关键。每一个“老和尚讲故事”的循环,都是对前一循环的总结和提升。黑格尔的辩证法教导我们,任何一个看似无解的矛盾,都包含着解决问题的种子。每一次循环,都是在过去的基础上进行反思和调整,从而达到新的认识高度。
在模型推理中,类似的循环也可以被视为一种不断修正和改进的过程。每当模型在推理过程中陷入困境,或者产生幻觉时,这实际上为我们提供了一个机会,去重新审视模型的推理路径,调整其决策机制。
或许我们可以思考,将这种循环作为一种学习的机会,而非仅仅是一个需要避免的错误模式。通过在每一个循环中积累新的经验和知识,模型可以逐步减少错误,最终走出循环,达成更高的推理水平。
我们看似被困在一个无尽的循环中,但每一次的反复,其实都为我们提供了通向更高理解的阶梯。模型的推理能力,也许正是在这样不断的循环和反思中,逐步提升的。
最终,我们要意识到,循环本身并不是问题,关键在于我们如何利用它,来促进模型的成长和进化。
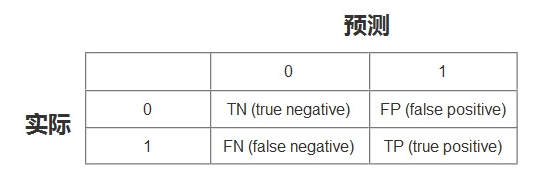
其中
TN:将负类预测为负类(真负类)
FN:将正类预测为负类(假负类)
TP:将正类预测为正类(真正类)
FP:将负类预测为正类(假正类)
准确率 (Accuracy)
测试样本中正确分类的样本数占总测试的样本数的比例。
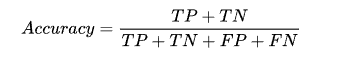
准确率又叫查准率,测试样本中正确分类为正类的样本数占分类为正类样本数的比例。
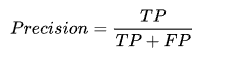
召回率又称查全率,测试样本中正确分类为正类的样本数占实际为正类样本数的比例。
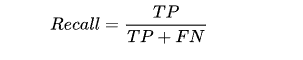
F1 值是查准率和召回率的加权平均数。F1 相当于精确率和召回率的综合评价指标,对衡量数据更有利,更为常用。
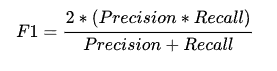
预测的正类中实际正实例占所有正实例的比例。(跟召回率一样的计算公式)
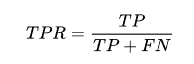
预测的正类中实际负实例占所有负实例的比例。
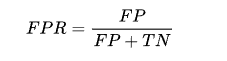
我们想要评估模型的能力,在阈值不同的情况下,TPR和FPR 又不一样,突然迷惘起来,这个时候,需要找到一个唯一评判标准,最值有唯一性,上图红色部分表示TPR-FPR,那我们就用最高点作为模型能力的评估标准吧!!对,没有错,最高点就是所谓的KS值,我们用KS值来作为评估模型区分能力的指标,KS值越大,模型的区分能力越强。公式如下:
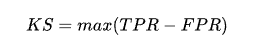
ROC的全称是“受试者工作特征”(Receiver Operating Characteristic)曲线,首先是由二战中的电子工程师和雷达工程师发明的,用来侦测战场上的敌军载具(飞机、船舰),也就是信号检测理论。之后很快就被引入了心理学来进行信号的知觉检测。此后被引入机器学习领域,用来评判分类、检测结果的好坏。
还是以上的TPR和FPR值,以上我们知道了KS值能表示模型的区分能力,我们只在阈值等于KS值时,觉得模型是好的,这样忽视掉了阈值取其他值的情景,有没有一种评估标准,无关阈值的取值呢?
在实际应用场景中,模型预测了一个样本集,在预测为正类中,我们当然希望的是,预测为正类的样本中,实际也为正类样本的比例越高越好,预测为正类的样本中,实际为负类样本的比例越小越好,也就是说,TPR越大越好,最好等于1,FPR越小越好,最好等于0,可是没有这么完美的事情,TPR变大的同时,FPR也会变大。数学家是聪明的,同时变化是吧,变化的速度总是有区别的吧?
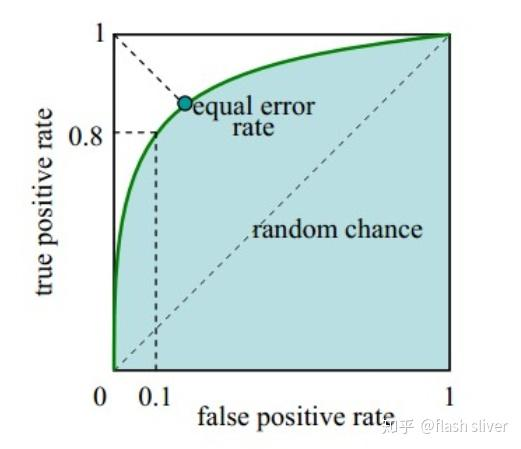
我们随机取很多阈值,得到很多FPR和TPR。用 X轴表示FPR,Y轴表示TPR,绘制上图曲线,这个曲线就是ROC曲线。(0,0)和(1,1)这两个坐标点根据实际情况,我们知道是固定的,假如两者的变化率是一样的,也就是说是一条过(0,0) 和(1,1) 的直线,此时斜率为1,也就是说随着阈值的变化,FPR和TPR 都同等程度变化。绘制出了曲线,是否可以用曲线的特性来表示模型的能力呢?我们希望得到的是:
到这里,我们又找到了一个评估模型的指标,对,就是图中的阴影面积,观察发现,我们可以用这个阴影面积的大小,来反应上面我们希望得到的特性,这个阴影面积的大小叫做AUC值。
AUC(Area Under Curve) 被定义为ROC曲线下的面积,因为ROC曲线一般都处于y=x这条直线的上方,所以取值范围在0.5和1之间,使用AUC作为评价指标是因为ROC曲线在很多时候并不能清晰地说明哪个分类器的效果更好,而AUC作为一个数值,其值越大代表分类器效果更好。需要注意的是AUC是一个概率值,当随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的分数将这个正样本排在负样本前面的概率就是AUC值。所以,AUC的值越大,当前的分类算法越有可能将正样本排在负样本值前面,既能够更好的分类。
相关资讯
热门资讯







