
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 本 qiang~ 这两周关注到一个很火的开源文档问答系统 Kotaemon ,从 8 月 28 日至今短短两周时间, github 星标迅猛增长 10K ,因此计划深挖一下其中的原理及奥秘。
本篇主要是 Kotaemon 的简介信息,涉及到主要特点,与传统文档 RAG 的区别,如何部署、以及效果演示 。
后续内容会针对核心模块进行拆解研读,敬请期待 ~
Kotaemon 是一个 RAG UI 页面,主要面向 DocQA 的终端用户和构建自己 RAG pipeline 的开发者 。
1) 提供了一个基于 RAG 问答的简单且最小化的 UI 界面
2) 支持诸多 LLM API 提供商 ( 如 OpenAI, Cohere) 和本地部署的 LLM( 如 ollama 和 llama-cpp-python)
1) 提供了一个构建 RAG 文档问答 pipeline 的框架
2) 使用 Gradio 开发,基于提供的 UI 可以自定义并查看 RAG pipeline 的运行过程
1) 托管自己的 QA Web UI: 支持多用户登录,支持文件私有或公开,支持与他人协助分享
2) 管理 LLM 和 Embedding 模型 : 支持本地 LLM 和流行的 API 提供商
3) 混合 RAG pipeline: 支持全文本和向量的混合检索,以及 re-ranking 来保障检索质量
4) 支持多模态文档:支持对含有图片及表格的 N 多个文档进行问答,支持多模态文档解析
5) 带有高级引文的文档预览 : 系统默认提供具体的引用信息,保障 LLM 回答的准确性。直接在浏览器内的 PDF 查阅器查看引文,并高亮显示。
6) 支持复杂推理方法:使用问题分解来回答复杂 / 多跳问题。支持使用 ReAct 、 ReWoo 及其他 Agent 进行推理
7) 可调节的设置 UI :调整检索和生成过程的参数信息,包括检索过程和推理过程设置

(1) 在 web ui 界面直接 PDF 预览,并通过 LLM 的引用回调方法高亮有关联的句子,极大地有助于仔细检查 LLM 的上下文
(2) 支持复杂推理方法。目标是支持更多的基于 Agent 的推理框架,如问题拆解、多跳问题、 React 、 ReWoo 等
(3) 支持在页面配置中更改 prompt ,也可以调整想要使用的检索和推理模块
(4) 扩展性好,基于 gradio 开发,可轻松添加或删除 UI 组件来自定义 RAG pipeline
- 可在 github 的 release 页面下载最新的 kotaemon-app.zip ,并解压缩
- 进入 scripts ,根据系统安装,如 windows 系统双击 run_windows.bat , linux 系统 bash run_linux.sh
- 安装后,程序要求启动 ketem 的 UI ,回答 ”继续”
- 如果启动,会自动在浏览器中打开,默认账户名和密码是 admin/admin
|
# 运行 docker run -e GRADIO_SERVER_NAME=0.0.0.0 -e GRADIO_SERVER_PORT=7860 -p 7860:7860 -it --rm ghcr.io/cinnamon/kotaemon:latest # 访问 ui 地址: http://localhost:7860/ |
|
# 创建虚拟环境 conda create -n kotaemon python=3.10 conda activate kotaemon
# 下载源码 git clone https://github.com/Cinnamon/kotaemon cd kotaemon
# 安装依赖 pip install -e "libs/kotaemon[all]" pip install -e "libs/ktem"
# 更新环境变量文件 .env ,如 API key # ( 可选 ) 如果想浏览器内部展示 PDF ,可以下载 PDF_JS viewer ,解压到 libs/ktem/ktem/assets/prebuilt 目录
# 开启 web 服务,并使用 admin/admin 登录 python app.py |
应用数据默认保存在 ./ktem_app_data 文件,如果想要迁移到新机器,只需将该文件夹拷贝即可。
为了高级用户或特殊用途,可以自定义 .env 和 flowsetting.py 文件
(1)flowsetting.py 设置
|
# 设置文档存储引擎 ( 该引擎支持全文检索 ) KH_DOCSTORE=(Elasticsearch | LanceDB | SimpleFileDocumentStore)
# 设置向量存储引擎 ( 支持向量检索 ) KH_VECTORSTORE=(ChromaDB | LanceDB | InMemory)
# 是否启用多模态 QA KH_REASONINGS_USE_MULTIMODAL=True
# 添加新的推理 pipeline 或修改已有的 KH_REASONINGS = [ "ktem.reasoning.simple.FullQAPipeline", "ktem.reasoning.simple.FullDecomposeQAPipeline", "ktem.reasoning.react.ReactAgentPipeline", "ktem.reasoning.rewoo.RewooAgentPipeline", ] ) |
(2).env 设置
该文件提供另一种方式来设置模型和凭据。
|
# 可以设置 OpenAI 的连接 OPENAI_API_BASE=https://api.openai.com/v1
OPENAI_API_KEY= OPENAI_CHAT_MODEL=gpt-3.5-turbo OPENAI_EMBEDDINGS_MODEL=text-embedding-ada-002 |
(1) 推荐 Ollama OpenAI 兼容的服务
|
# 安装 ollama 并启动程序,可参考 https://github.com/ollama/ollama
# 拉取模型 ollama pull llama3.1:8b ollama pull nomic-embed-text |
(2) 在 Resources 页面中的 LLMs 和 Embedding 分别设置 LLM 和 Embedding
|
api_key: ollama base_url: http://localhost:11434/v1/ model: llama3.1:8b (for llm) | nomic-embed-text (for embedding) |
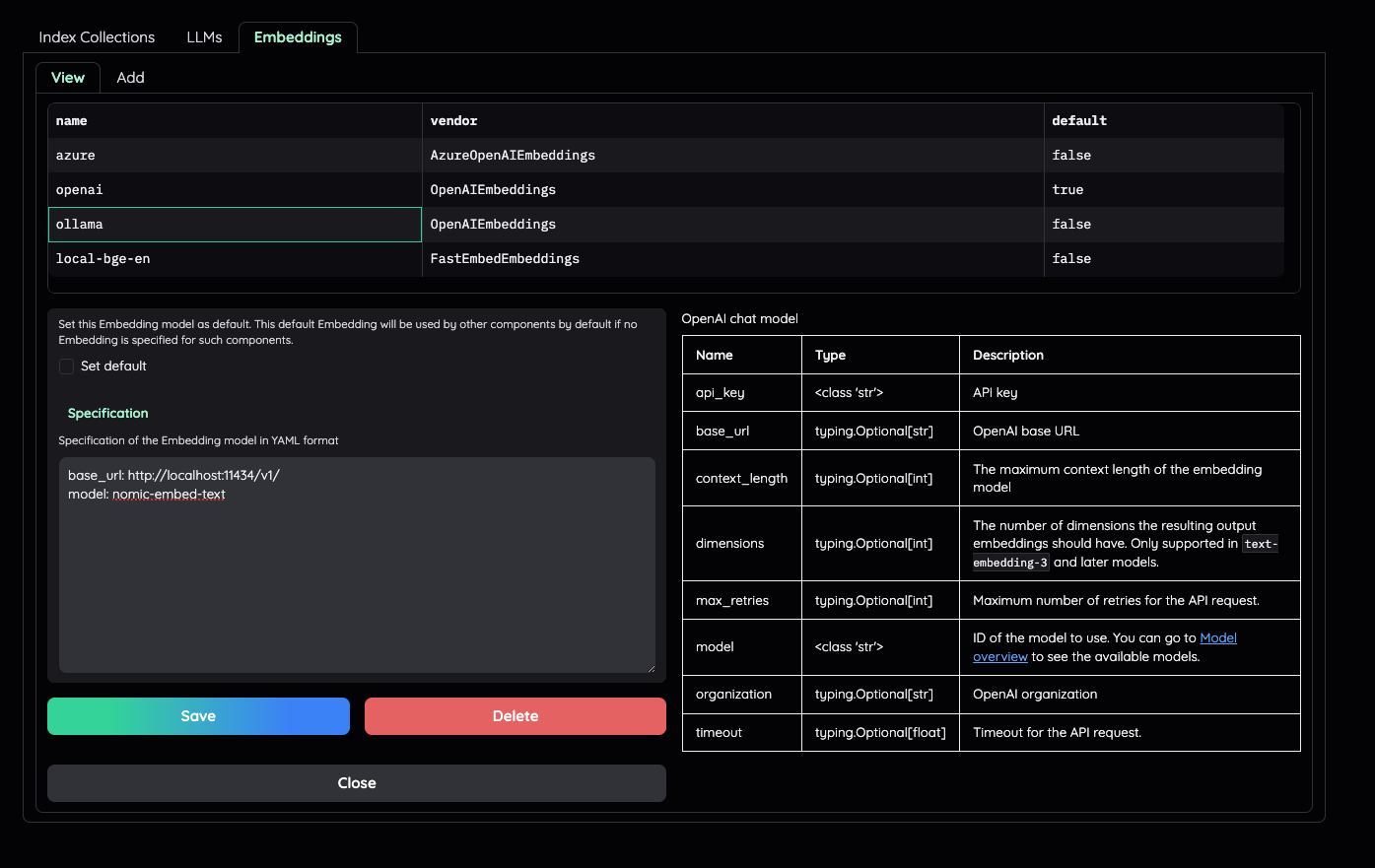
(3) 使用本地模型用于 RAG
1) 将本地 LLM 和 Embedding 模型设置为 default
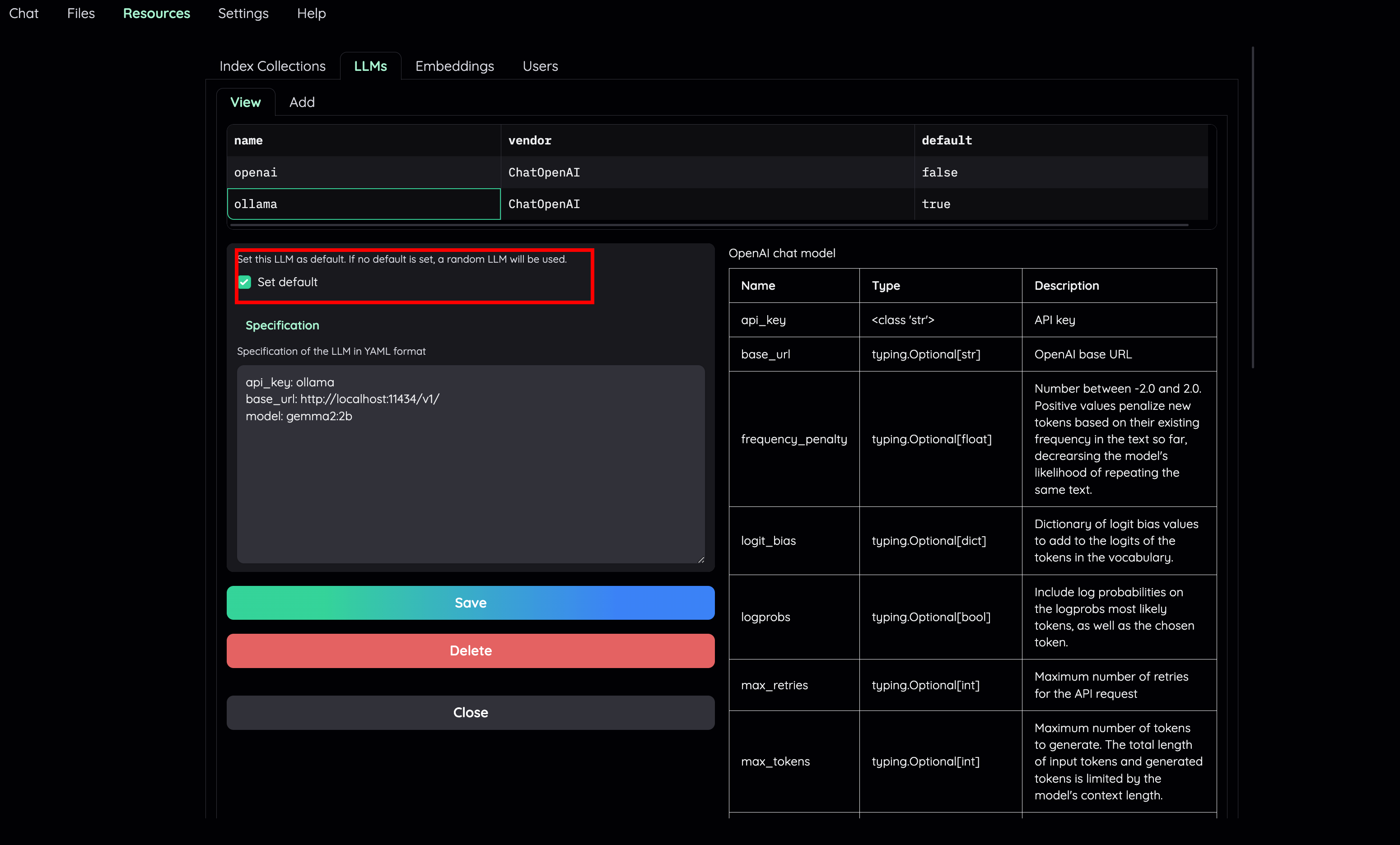
2) 将 File Collection 中的 Embedding 设置为本地模型 ( 例如 : ollama
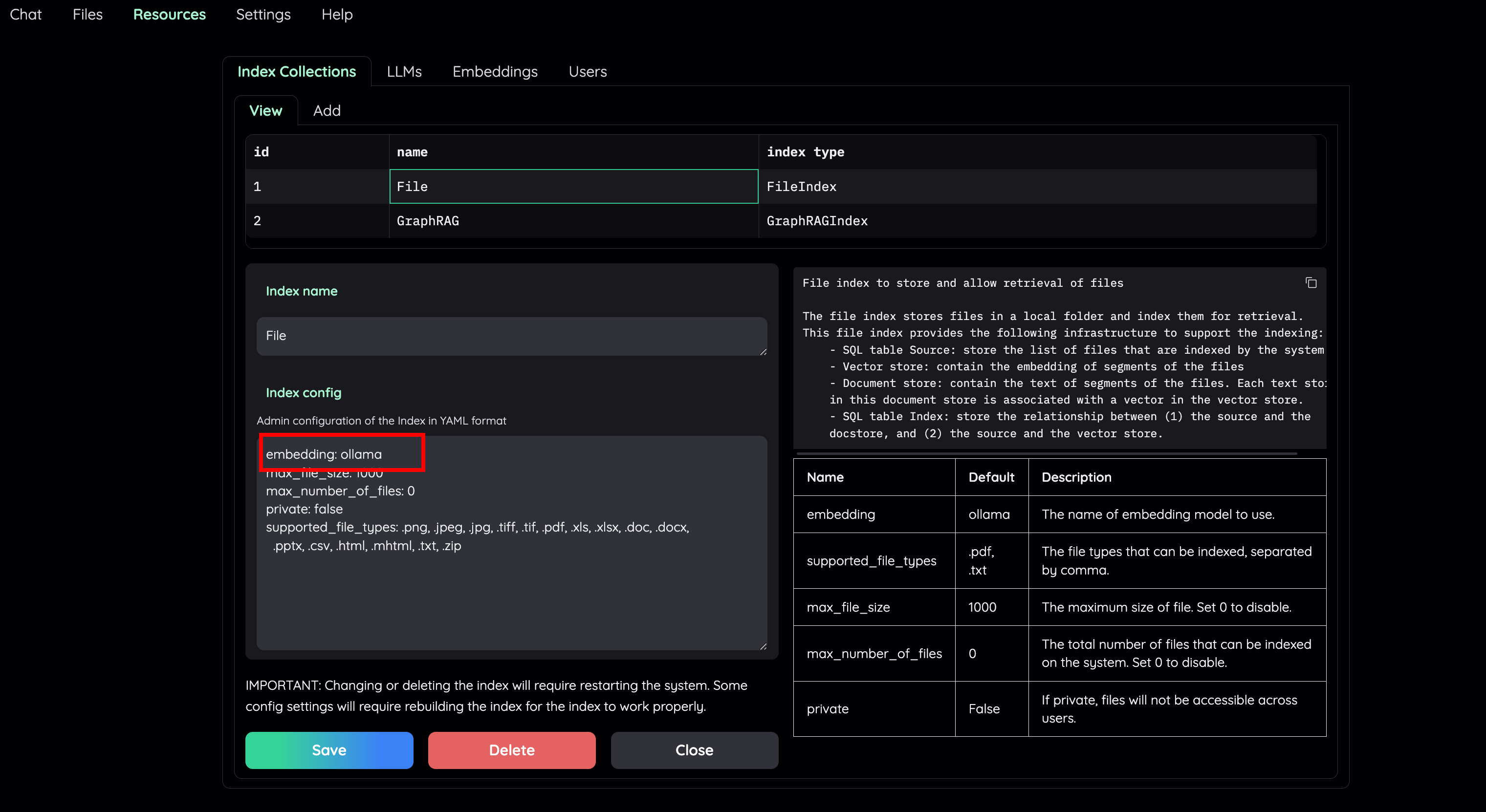
3) 在 Retrieval Setting 页面,选择本地模型作为 LLM 相关得分模型。如果你的机器无法同时处理大量的 LLM 并行请求,可以不选中 ” Use LLM relevant scoring ”
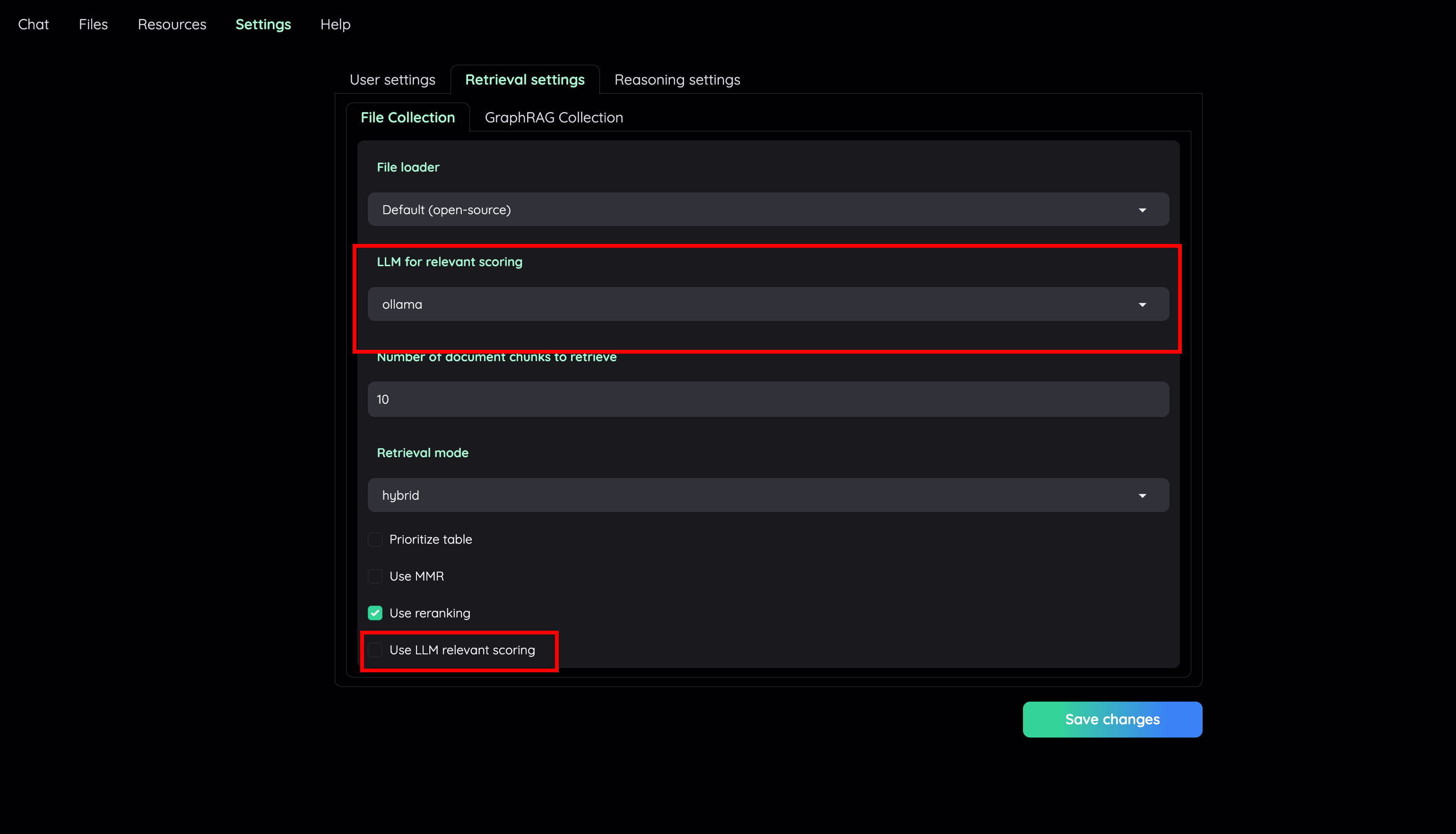
4) 现在就可以上传文件进行文档问答体验了。
眼过千遍,不如手过一遍 ~
本 qiang~ 采用源码安装部署,使用 openai 的 LLM 模型 gpt-4o-mini 和 Embedding 模型 text-embedding-3-small( 如何使用免费版本的 openai 进行 api 体验,可以私信联系 ~) 。其次,使用 MindSearch 的论文进行测试验证。
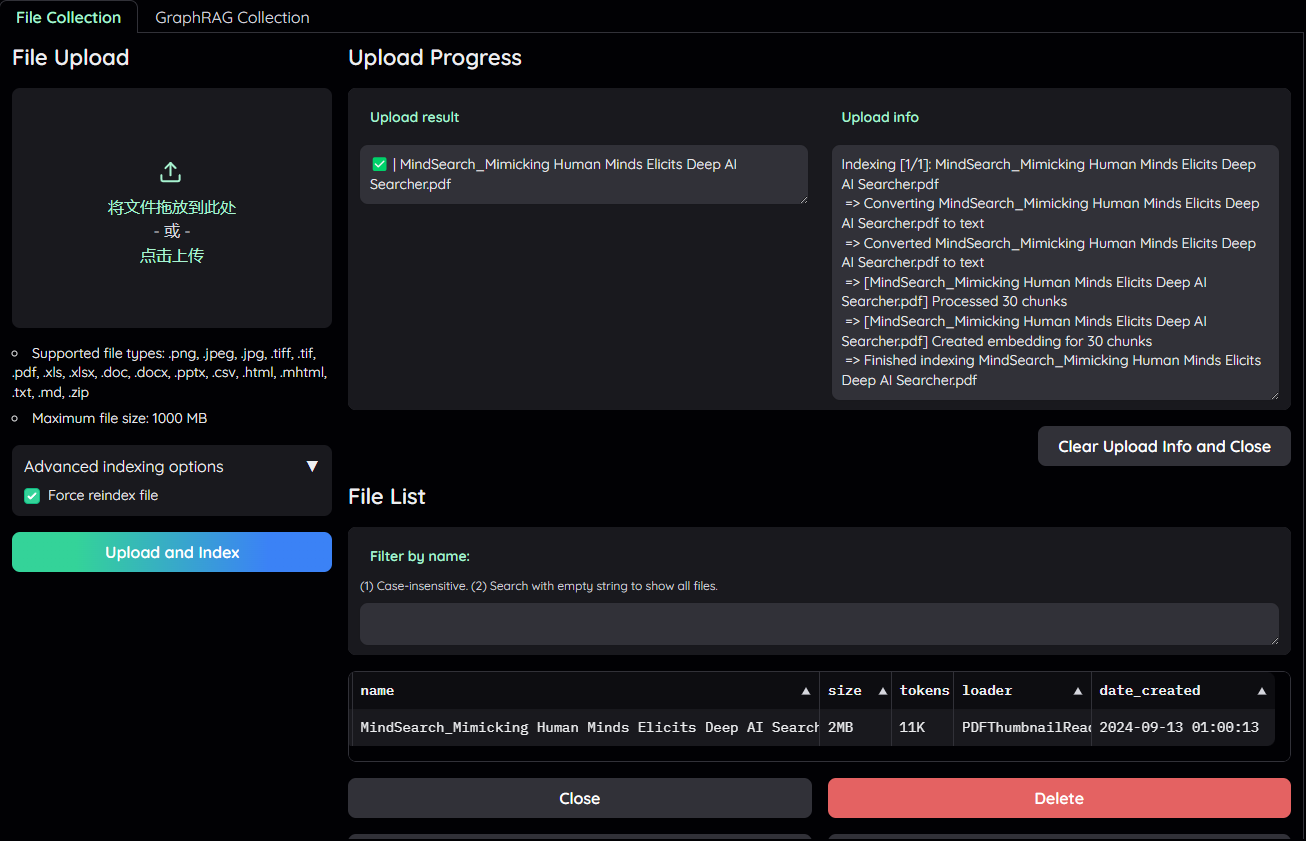
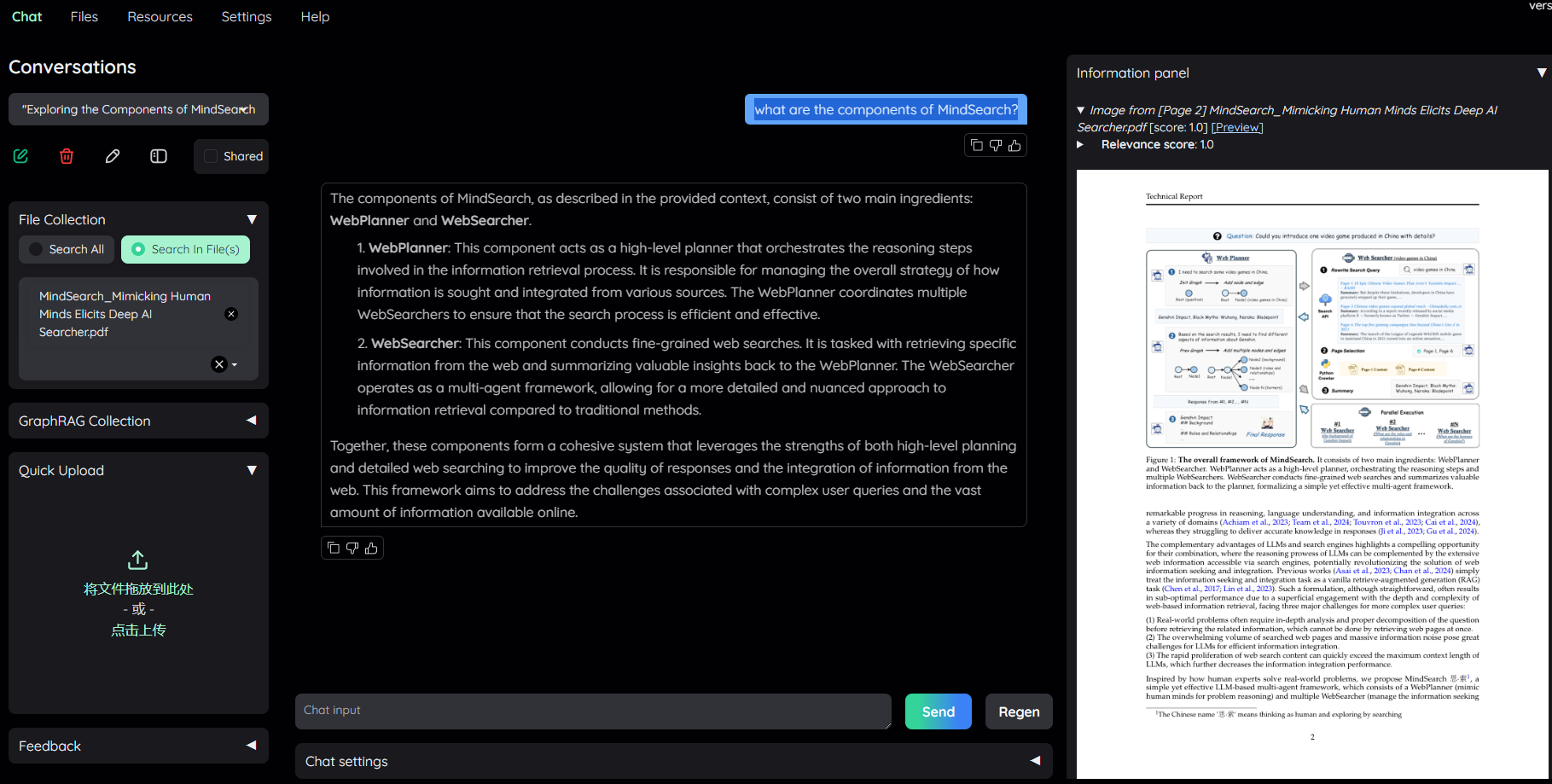
simple 推理策略对应的 flowsettings.py 中的 FullQAPipeline 。问题 : “what are the components of MindSearch?”,效果如下:
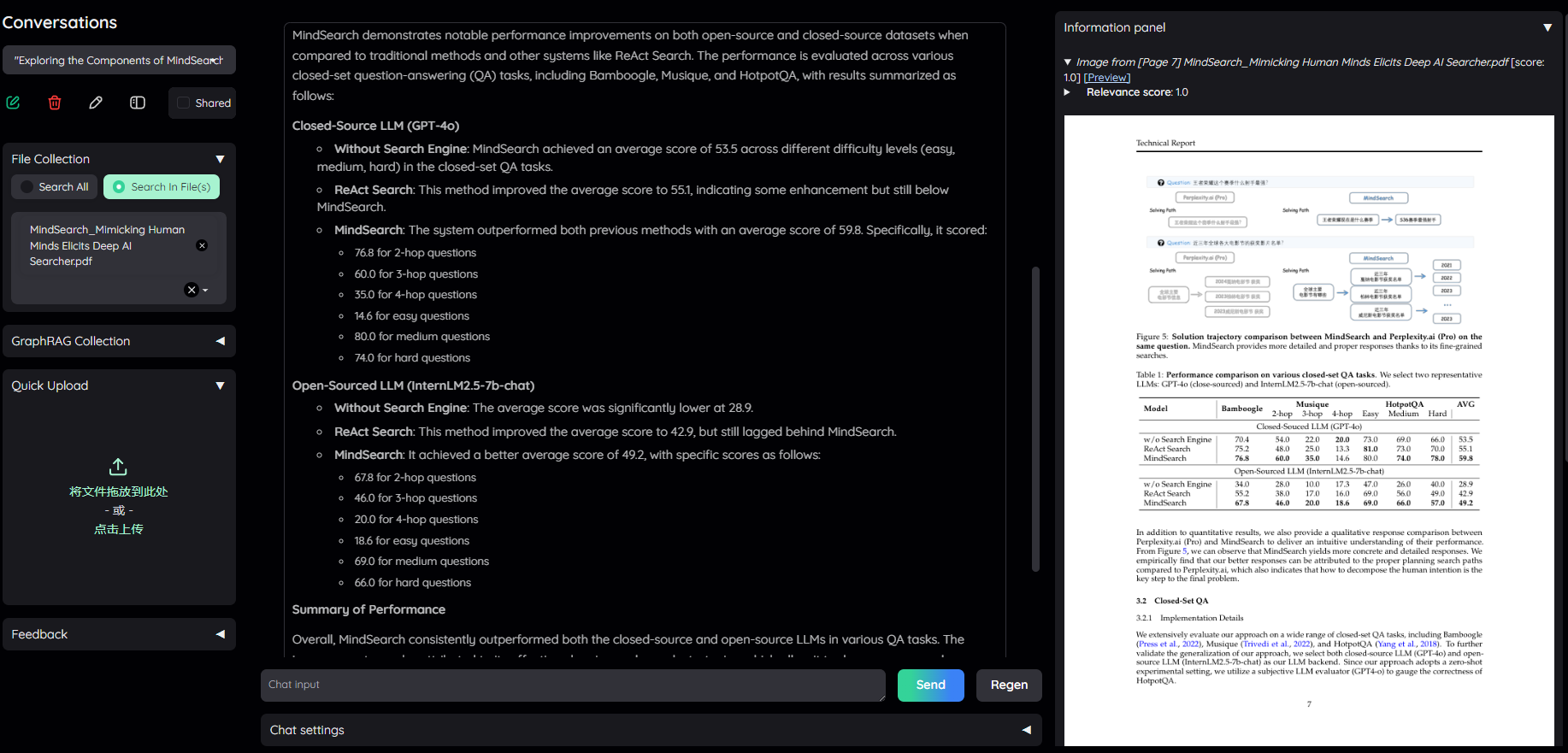
complex 推理策略对应的 flowsettings.py 中的 FullDecomposeQAPipeline ,即将复杂问题拆分为简单子问题。问题 : “Please describe the performance of MindSearch on both open-source and closed-source datasets.?”
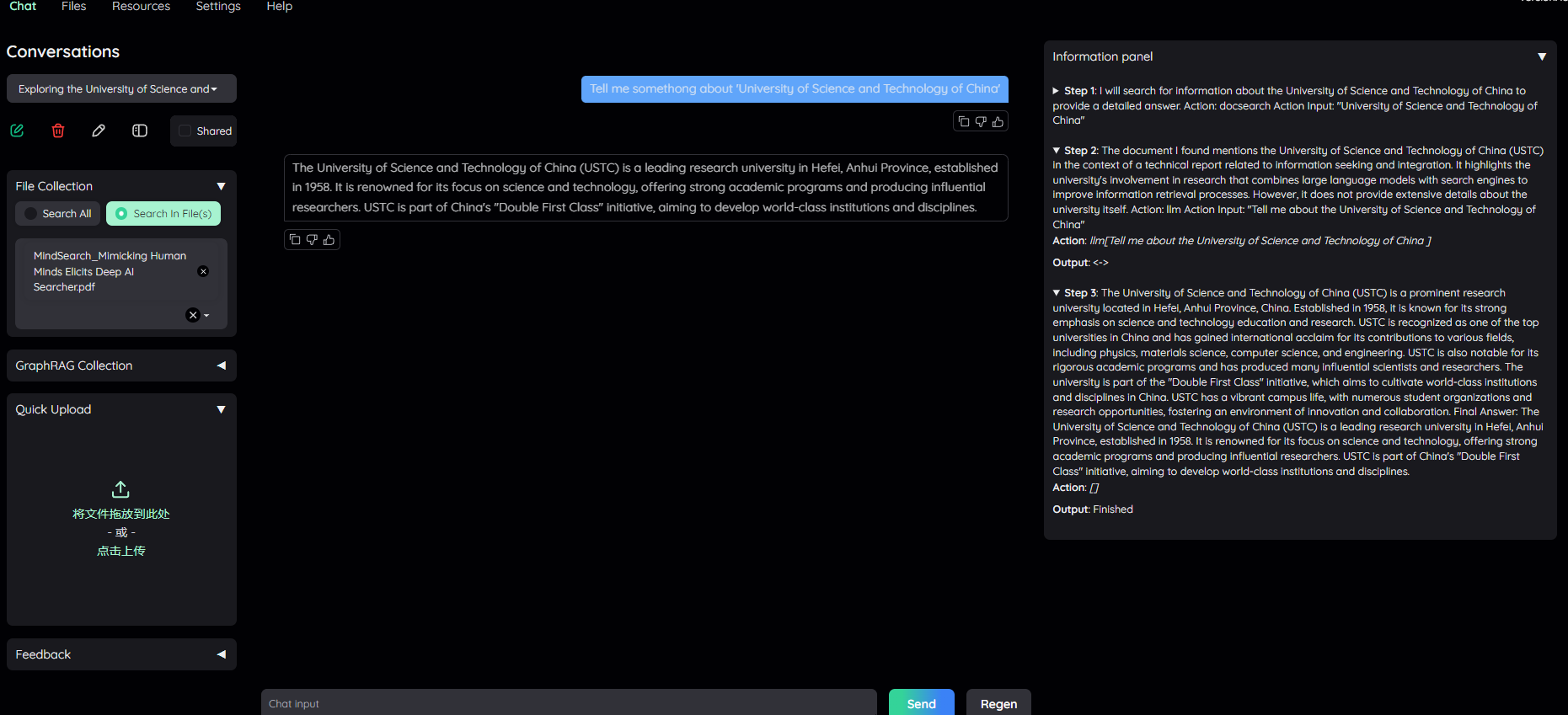
React 是一种 RAG Agent 技术,将用户的问题进行计划设计,并迭代循环执行,满足特定结束调节。 React 可以结合工具进行调用,如搜索引擎、 Wiki 百科等。问题: ”Tell me somethong about 'University of Science and Technology of China'”
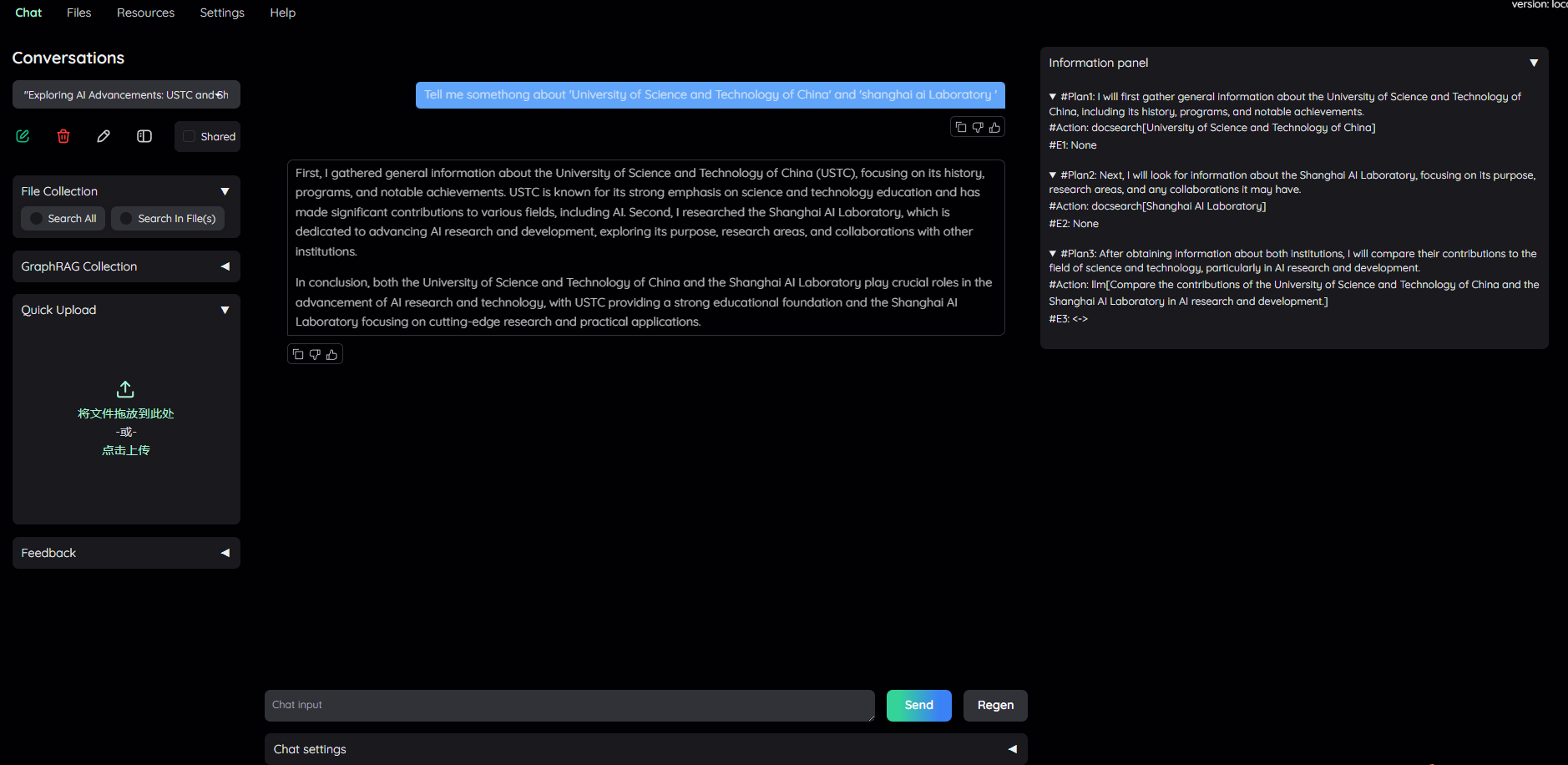
ReWoo 也是一种 RAG Agent 技术,第一阶段制订分步计划,第二阶段解决每个分步,也可以使用工具帮助推理过程,完成所有阶段后, ReWoo 将总结答案。问题: ”Tell me somethong about 'University of Science and Technology of China' and 'shanghai ai Laboratory '”
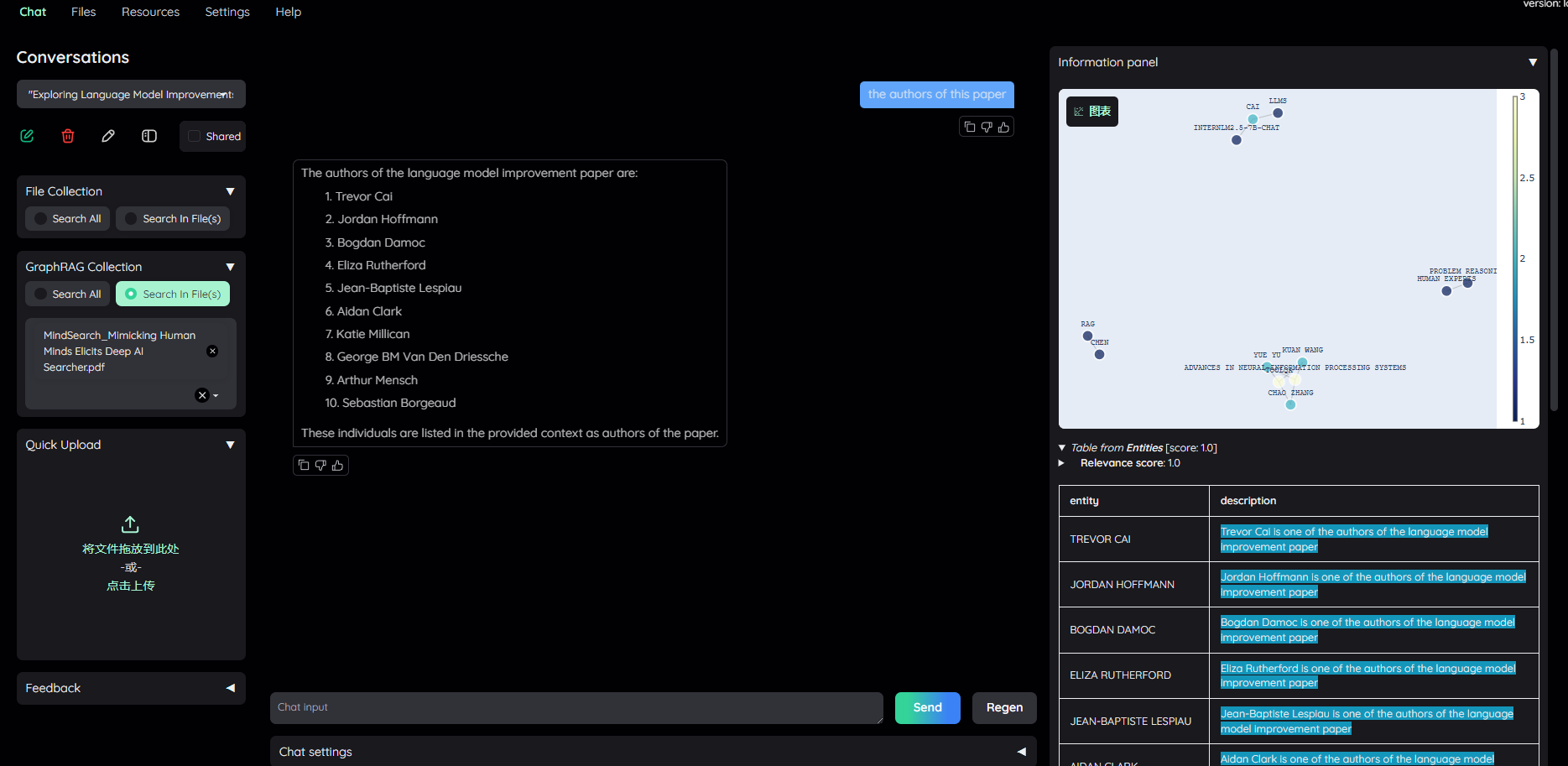
Kotaemon 集成了微软此前开源的 GraphRAG 框架,该框架包含图谱及索引构建、图谱检索等步骤。问题 : “ the author ’ s of this paper ”
一句话足矣 ~
本文主要针对开源文档问答系统 Kotaemon 的介绍,包括主要功能特点,与传统文档 RAG 的区别,部署教程以及效果体验等。
目前 Kotaemon 针对中文语言支持不友好,但既然可以通过 ollama 进行部署 LLM 和 Embedding 模型,因此支持中文语言也是相对容易开发集成的。
后续系列会针对该框架中的检索和推理模块做一个详细的源码维度分析,敬请期待 ~
如果针对部署过程中存在疑问或部署不成功,或者想免费获取使用 openai 的客官,可私信沟通。
如有问题或者想要合作的客官,可私信沟通。
(1) Kotaemon 仓库 : https://github.com/Cinnamon/kotaemon

热门资讯







