
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 首先给大家介绍一个很好用的学习地址: https://cloudstudio.net/columns
聚类是一种无监督学习方法,其基本假设是数据集未经过标记,或者输入数据与预定义的输出之间并不存在直接的对应关系。聚类的主要目标是将具有相似特征的数据点归类到同一组中,这一组通常被称为“簇”。
聚类结果的质量和有效性往往依赖于数据点之间的距离度量,进而影响到分组的准确性和合理性。通过聚类分析,研究人员能够发现数据的内在结构,进而为后续的数据处理和决策提供有价值的参考。
在我们的日常生活中,当我们面临需要整理一堆家人的衣物时,实际上就是在进行一种聚类的过程????。我们根据衣物的种类、颜色、大小等特征,将相似的衣物归类到一起,以便于整理和存放。这一简单的生活场景与数据科学中的聚类方法有着密切的联系。在数据科学领域,聚类被广泛应用于分析用户的偏好、识别市场趋势或确定任何未标记数据集的潜在特征。
通过将相似的数据点分组,聚类帮助我们更清晰地理解复杂的信息,从而在某种程度上使我们能够更好地处理杂乱的状态。
聚类,简单来说,就是将数据进行分类或归类的过程。然而,如何有效地进行这种归类是各类算法需要深入研究和考虑的重点。在这个过程中,我们会遇到许多专有名词,这些术语的理解对于掌握聚类方法和算法至关重要。
转导推理源自观察到的映射到特定测试用例的训练用例。归纳推理源自映射到一般规则的训练案例,然后才应用于测试案例。听不懂没关系,我来举个例子。
简单举个例子来说明转导推理和归纳推理的区别。
首先了解下归纳推理:
在这个过程中,你从具体的观察(具体的白色天鹅)推导出一个一般性的结论(所有天鹅都是白色的)。但是,这个结论并不一定正确,因为你没有观察到所有的天鹅。
其次是转导推理:
在这个过程中,你从一般性的规则(所有天鹅都是鸟)推导出一个特定的结论(这只天鹅是鸟)。这个结论是逻辑上必然的,只要前提成立。
所以说简单来说就是:
平面几何是在二维平面上(例如纸面)进行的几何图形。基本的对象包括点、线、面、角、三角形、四边形等。如:在平面上绘制一个三角形,测量边长和角度,使用欧几里得几何的规则,如勾股定理。
非平面几何研究的是在三维空间或更高维空间中的几何特性。它包括非欧几里得几何,如椭圆几何和双曲几何。如:在球体表面上研究几何,像是测量大圆(在球面上的“直线”),例如地球上的最短路径(航线)。
几何与机器学习有着密切的关系,数据常常以几何形状的形式存在。例如,点云数据、图像和视频可以视为在高维空间中的点。比如:在处理图像、社交网络等非欧几里得数据时,可能需要使用非欧几里得几何的概念来分析数据的结构和关系,再或者通过几何方式,可以衡量不同数据点之间的相似性,从而帮助分类和聚类任务。
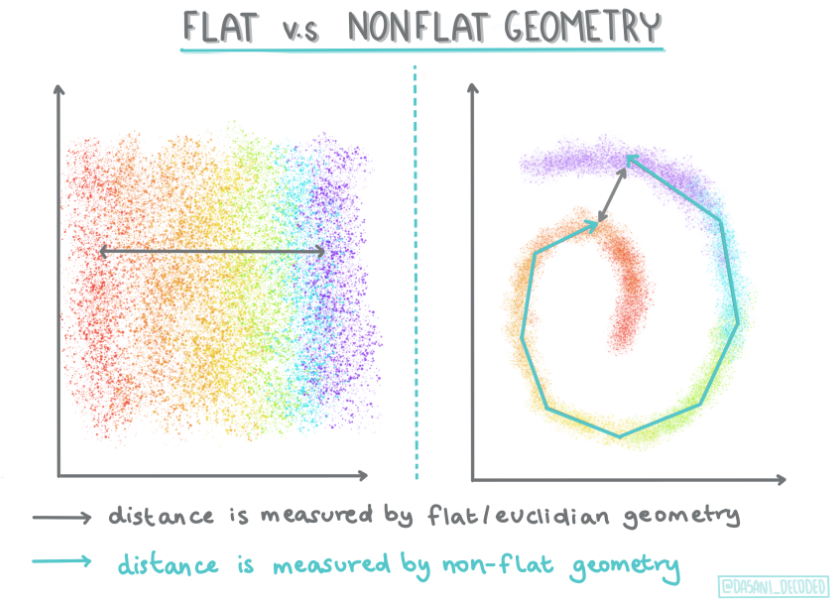
聚类由它们的距离矩阵定义,例如点之间的距离。这个距离可以通过几种方式来测量。欧几里得聚类由点值的平均值定义,非欧式距离指的是“聚类中心”,即离其他点最近的点。我来句几个例子讲解一下啥意思。
距离矩阵:距离矩阵是一个表格,记录了数据集中每对点之间的距离。行和列表示数据点,矩阵中的每个元素表示对应点之间的距离。
欧几里得距离:这是最常用的距离测量方法,适用于计算在二维或三维空间中点之间的直线距离。在聚类中,欧几里得聚类的“质心”是指所有点的平均位置。你可以想象质心是每个簇的“中心”。
非欧几里得距离:指不遵循欧几里得几何规则的距离计算方式。例如,曼哈顿距离、切比雪夫距离等。这些距离通常反映了不同的空间特性。
示例再说明,假设我们有以下数据点:
欧几里得聚类:
非欧几里得聚类:
约束聚类是一种结合了无监督学习和半监督学习的方法。它通过引入一些额外的约束条件来指导聚类过程,从而提高聚类的质量和效果。以下是一些关键点:
约束的类型:
举例分析一下,假设我们在聚类一组物品,其中包括:
在没有约束的情况下,算法可能会将圆形和方形玩具分到同一个簇中,而将三角形玩具和饼干分到另一个簇,因为算法仅依赖于它们的特征。
但是,如果我们设定约束条件——“所有物品必须由塑料制成”,算法将只能考虑圆形和方形塑料玩具,因此它们会被正确聚到一起,而其他物品则不会干扰这个过程。
所以约束聚类通过提供指导性的信息(必须链接或无法链接),使得聚类算法能够更有效地处理数据,减少不相关物品的聚类,从而提升结果的质量。
在检查时,每个聚类中的点之间的距离可能或多或少地密集或“拥挤”,因此需要使用适当的聚类方法分析这些数据。
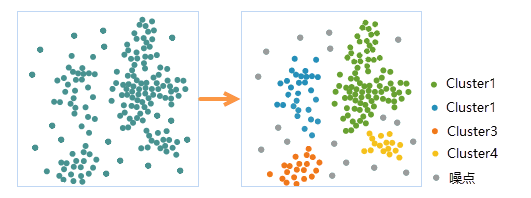
比如K-Means 适合用于簇的形状比较规则且密度较为均匀的数据集。对噪声敏感,嘈杂数据可能会干扰聚类结果。在不同密度的聚类中效果不佳。HDBSCAN 特别适合于数据密度不均匀的情况,可以自动识别和排除噪声。
因此,在选择聚类算法时,根据数据的特点和需求选择合适的方法非常重要。
聚类算法的种类繁多,超过 100 种之多,其适用性通常取决于具体数据的性质和分析目标。为了深入理解这些算法的特点,我们将重点介绍两种常见的聚类方法:层次聚类和质心聚类。
接下来,我们将通过具体的例子来阐述这两种算法的特点及其在实际应用中的效果。
层次聚类是一种通过建立数据点之间的层次关系来进行聚类的方法。它的主要思想是将数据点逐步合并成簇,形成一个树状结构(树形图或 dendrogram)。
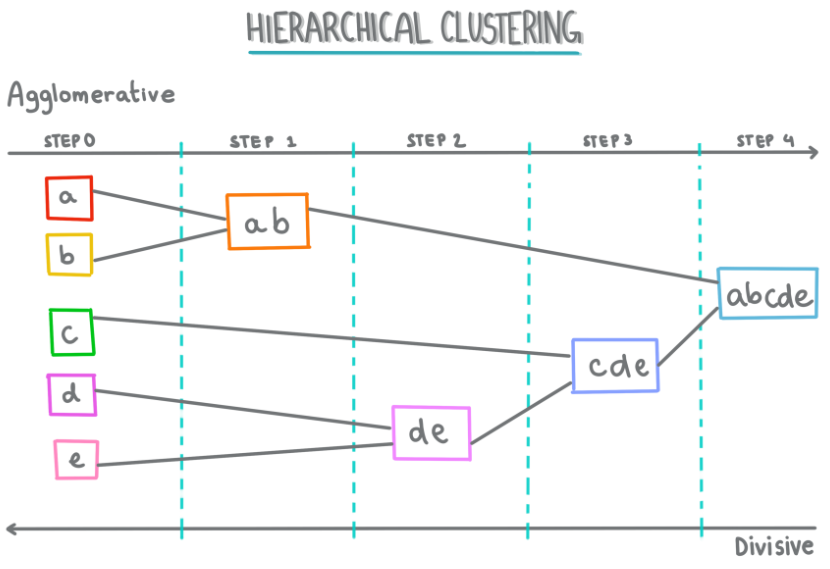
主要方法有两种,上面的图例则是自下而上的方法:
如果还是没懂,我们再举一些例子,假设我们有一组水果数据,包括苹果、橙子、香蕉和草莓。使用层次聚类,首先每个水果作为一个单独的簇,然后根据水果之间的相似性逐步合并,最终形成一个树状结构,展示出水果之间的关系。例如,苹果和橙子可能先合并,因为它们都是柑橘类,而香蕉和草莓则可能在之后的合并中形成新的簇。
质心聚类是一种基于质心(簇的中心点)来进行聚类的方法,最常用的例子就是 K-Means 算法。
K-Means 算法步骤如下:
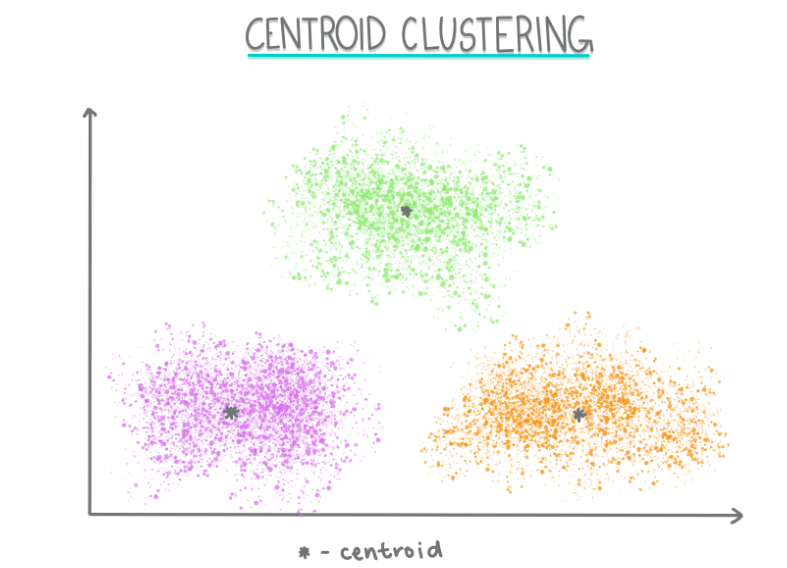
也举一些例子吧,假设我们有一组客户数据,基于他们的购买行为进行聚类。使用 K-Means,选择 k=3,可以将客户分为三类:频繁购买者、偶尔购买者和不活跃客户。算法会根据每类客户的购买习惯计算质心,并调整每个客户的归属,最终得到三个明确的客户群体。
这两类算法也有自己的局限性,层次聚类适合小规模数据集,能够生成数据的层次关系,易于可视化,但计算复杂度较高。质心聚类计算效率高,适合大规模数据集,但需要事先指定簇的数量,且对异常值敏感。
在本文中,我们探讨了聚类作为一种无监督学习方法的重要性与应用。聚类不仅帮助我们识别数据中的内在结构,还能在实际生活中提供灵感,例如我们日常整理衣物时的归类过程。通过理解距离矩阵、约束聚类及密度等概念,我们能够更准确地进行数据分析,并选择适合的聚类算法。无论是层次聚类还是质心聚类,每种方法都有其独特的优势和适用场景。
今天的前置知识就到此为止,希望大家能够迅速掌握这些基本概念,为后续学习打下良好的基础。在下一章节中,我们将深入探讨如何对数据进行聚类分析,期待与大家一起探索这一重要的主题。
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。同时也是一位腾讯云创作之星、阿里云专家博主、华为云云享专家、掘金优秀作者。
? 我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。
? 欢迎关注努力的小雨!?
热门资讯







